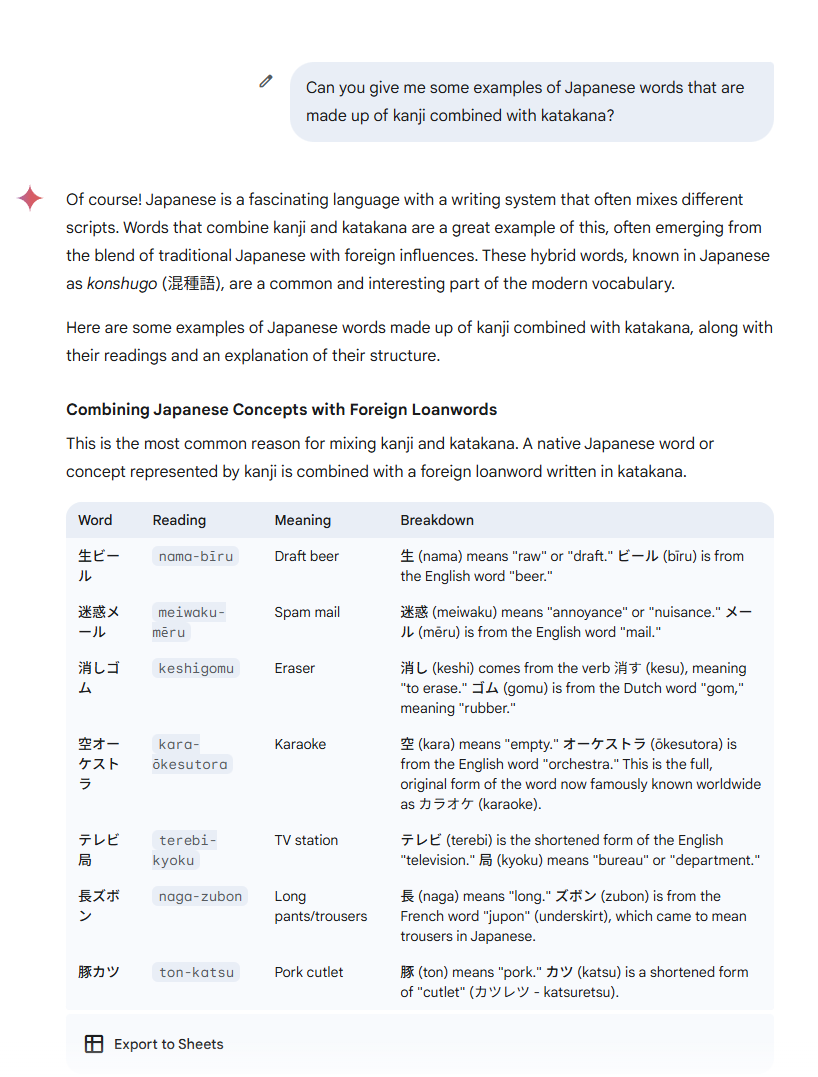
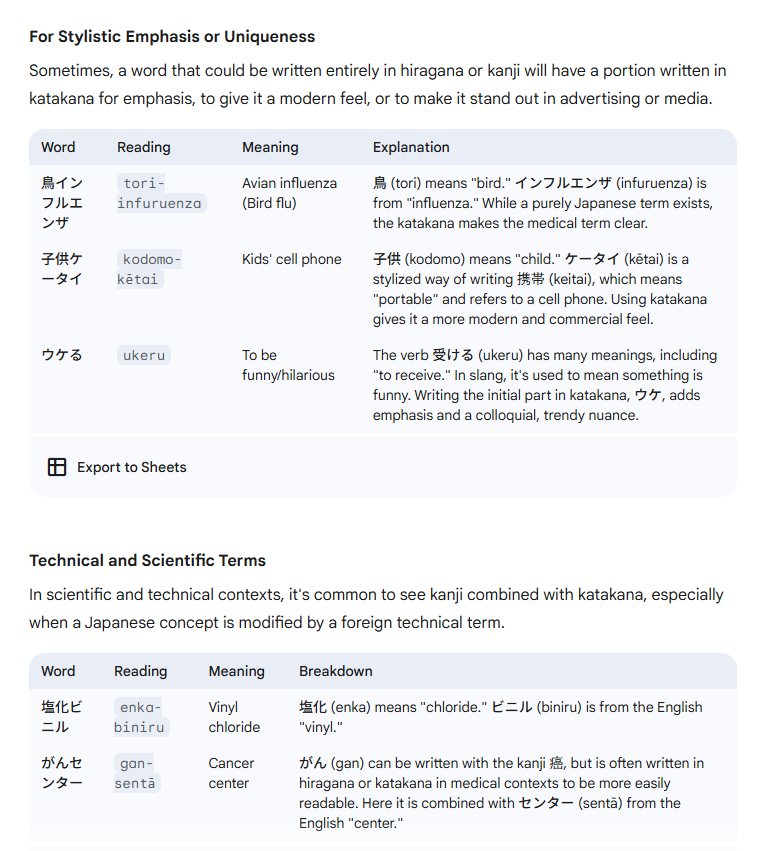
this is a fundamental misinterpretation of what an LLM is, it’s a text generator. The answer is simply a generated sequence of words based on what the most probable word is after the previous one. They are trained on a very simple task: Predict the next token (word or subword) given a squence of previous tokens.
Given: The cat sat on the ___
Learn to output: mat
this is called “casual language modeling”.
Doing this on a massive corpora of text (books, websites, code, more) exposes the LLM to a lot of linguistic variety. So much that it might give us the illusion that it is reasoning. But in the end it’s just a text generator. It will therefore hallucinate on the simplest topics with no guarantee whatsoever that what it is outputting makes the slightest sense. And trusting what it says comes with other dangers as per this study made by Microsoft.
Further reads:
Here’s a very simple example on how the chosen words (the token sequence) determine the response without any regard to what it actually outputted.


 .
.