
This is so cool! I loved the introduction of the Kansai-ben deck, and hopefully we will be able to build different dialect decks for the other areas now too. It’s the kind of thing that would be too small to request staff resources to be allocated to, but ideal as a community project. This will definitely make me use Bunpro even more than I do.
2 Likes
This please 
4 Likes
I tried updating the photo, but doesn’t seem to change from the one I originally updated even after a cache refresh.
2 Likes
Is there a way to add a card to a community deck through the vocab info page when doing reviews? I have so many vocab from games and manga all thrown together that I would like to separate out into different decks. If not, I hope this comes in the future.
2 Likes
@Jake This is great, thank you so much for getting this added to Bunpro! Could you also add ‘Game’ or ‘Video Game’ as a type when creating a deck?
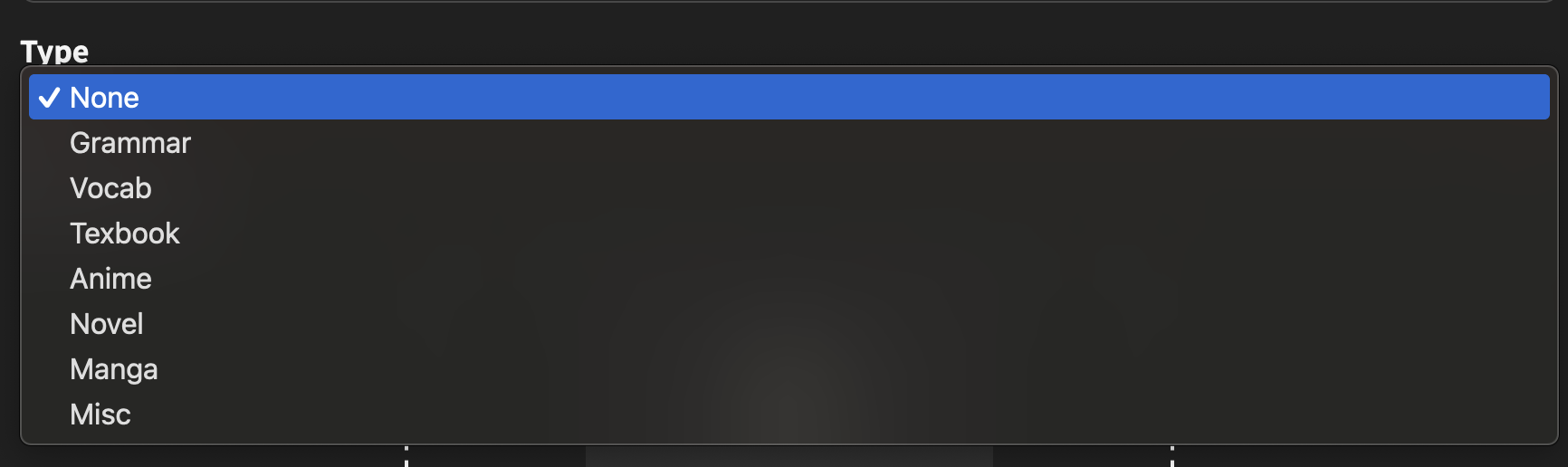
14 Likes
It could be interesting to have access to the API to generate decks from scripts, will this be planned ?
I guess this is one of the reasons to include deck generation via csv
4 Likes
Yes going to need to create a way to add-to-Deck through the individual Vocab pages as well as through Search pretty soon.
@haldo
As for API, nothing planned of yet… CSV support coming soon.
For CSV support, is there anything you want added/would be nice?
Literally in the process of building it right now.
10 Likes
This is incredible!
1 Like
I have created a deck for the textbook 新中級から上級への日本語 Authentic Japanese Progressing from Intermediate to Advanced [New Edition]. Deck available here. Grammar is broken down by chapter. Not all grammar points are on bunpro but I’ve included all I could find.
I’d been studying this textbook for a few months by adding the points individually so I hope this can save others a bit of time.
I had some errors with the title. Using the Japanese name wouldn’t let me edit and would take me to the ‘no decks match page’. And there’s a character limit on titles, so I couldn’t put the full English textbook name in either.
3 Likes
I added that option!
@adorable that is a perfect example of the kind of awesome deck we figured you all would come up with! Well done 🥹
6 Likes
It could be interesting to be able to add the name of the unit/description directly in the csv.
Possibly an option to reimport a csv for an existing deck to replace it/add item.
The complicated part remains to know how to differentiate the vocabulary/grammar in a single file and how to manage the items that are not present in the site resources.
Maybe present an option or a prompt to manage these cases.
2 Likes
I just finished a rough (but working) version of a script to automatically extract all vocab from a manga into a csv file to be imported to Bunpro: GitHub - Fluttrr/manga-wordlist-extractor
Can’t wait for the import feature to be released now, hope this script will help other people too!
11 Likes
Thank you so much! Will definitely have to use this once CSV imports get done. Do you (or anyone else) know if there’s an equivalent for novels?
1 Like
If you have a PDF that you can just copy all the text out of, I could easily make it work with text files too. If they’re images this script might work with them? The models are trained on manga but some of them should work okay on other forms of media too. Otherwise I’m not aware of any other options, but I also haven’t really done any research on anything other than manga (because anything else is covered pretty well by jpdb)
3 Likes
I might be able to extract the novel file from an epub.  Never tried it, but it seems like something that should be doable. Extracting from an epub would be the best solution, I would think (less need to convert to other formats), but if your text extractor is able to accommodate PDFs, all the better.
Never tried it, but it seems like something that should be doable. Extracting from an epub would be the best solution, I would think (less need to convert to other formats), but if your text extractor is able to accommodate PDFs, all the better.
1 Like
I just mean any format that you can open in some sort of viewer, hit CTRL+A, copy all the text and just put it into a text file. Actually working with PDFs or epubs directly is probably a pain, unless There’s a way to just automatically extract all the text in one go, I’d have to look into that. But implementating a pure text extractor would probably be really easy. (I say probably because the thing I’m using to get vocab from sentences is pretty flawed with verbs, I’ll just have to look into alternatives before the feature actually comes out)
3 Likes
Whoops, I must’ve misread your original post, haha. Anyway, would definitely be something I’d need to look into, seeing how easy it would be to set it up so the entire novel is captured in ctrl + a.
1 Like
There are a bunch of tools and package you can use to convert PDFs to plain text, either through the command line or python modules. See for instance PDFMiner
There are also python libraries to manipulate epub files but I have no familiarity with them: EbookLib · PyPI
2 Likes
Thank you a lot, I’ll look into that!
1 Like
Hi, thank you for doing this. Maybe @Asher or @Jake could contact you to get the missing vocab added.
As I think this will be most beneficial for every one learning Japanese!
This is indeed exactly why it’s great that this exists. So thank you so much at the whole team.
@Jake you requested what you need for important tool? Well I have an idea.
The great bookclub users on Wanikani uses excel sheet for vocab (I think most of them if not all uses the same format) Would be great if this could be added as import template structure.
I would hope that much of the data is preserved. As in useful remarks. So it will be come useful at its best. This would also save as an back up in case deletion of said forums.
If all data is added it can also mean bookclub users will start using this in addition.
If not I will not be the only one making same vocab list on here.
Hence the support for the format Wanikani uses.
1 Like