
You can totally do this yourself for any anime you want, you just need to get the subtitles from somewhere and use my tool to make your own vocab lists. I think the fact that any club can just make a deck for their own show/manga/novel with this feature will be really great.
3 Likes
I also just found a bug. I imported vocab for A Silent Voice and did it in batches of 250 words to avoid the errors. When I started renaming the untitled units, it created a bunch of “ghost units” that can’t be interacted with but that clog up the list. Those units cant be saved and when leaving the page, only the correct saved ones are left.
Also, on the import page, setting a description for the unit is required. On the regular deck creation page it is optional. I think it should probably be optional on both.
2 Likes
I totally missed this question btw, if you’re on Linux or MacOS you can use “split -l 500 INPUT_FILE chunk_” and just replace the INPUT_FILE. On Windows it might be a bit more complicated but honestly just ask some AI like ChatGPT, it gives really good answers for stuff like this
1 Like
@Sean Did a small test batch of 445 words. Failed with the import the first time, then succeeded the second. 413 words found and 34 not found. I’m going to put all my feedback in this one reply so it’s easy to find.
-
Could missing vocab/grammar be pulled to the top of the newly-created unit instead of the bottom, so you don’t have to scroll all the way down to see it? In addition, after further experiementation, might be nice to have a small line break or something in between the incorrectly-parsed stuff and the good stuff, so that once you start correcting the bad stuff, it’s still set aside from the general blob of hundreds of good items and you can keep a better eye on it in case you want to delete it/further change it.
-
For missing words, would it be possible as well for the parser to also attempt to match all-katakana words as all-hiragana? There are a lot of words that wouldn’t work for, granted, but I was thinking of stuff like にっこり、ジワジワ, both of which showed up in their “opposite forms” in the book but are valid with either syllabary.
-
Would also be nice if the parser was able to see a word with kanji, and search for not only the exact match but a word with some of the kanji subbed in by hiragana. Examples from my test import:
- (book) 出掛ける → (Bunpro) 出かける
- (book) 遣り繰り → (Bunpro) やり繰り
And vice-versa:
- (book) コツ → (Bunpro) 骨
Search for alternate kanji would be an extension of that, but I’m starting to tread deeper into “I don’t know how easy this would be for Bunpro’s backend to do right now” territory:
- (book) 止め金 → (Bunpro) 留め金
-
Future ask related to the above: the ability to save/retain the spelling the word was written in the book. 若し is a good example of this in my test book, where it’s used instead of もし, which could really trip up a learner. I’ve also read plenty of modern mystery novels where the author uses 云う instead of 言う, for example.
-
Another question: I set my new deck as type “Novel”, but it doesn’t seem to want to pull in grammar points? ぞ shows up on my imported word list, and it’s definitely referring to the sentence-ending particle, but because that’s classified as grammar the parser can’t find it. Or if it can, it’s buried in the list of hundreds of results that include ぞ somewhere in them, which definitely isn’t helpful.
-
Another ask: similiar to how correcting a bad parser item to a recognized Bunpro item shows the original alongside the new and allows you to further edit it if wanted:

Could the same be done with stuff I delete? If I accidentally delete something right now it’s gone forever, and it’d be nice to easily undo it if I click the wrong item to delete or realize there was another search term I could’ve tried instead. -
I haven’t come across an example of this yet (ぞ, maybe, relating to my above bullet point), but another thought: the deck doesn’t let you save until you’ve corrected all the import errors, but it would be nice if there was an option to “save” the ones with no Bunpro parse seperately, so that if you know it’s a grammar point/vocab item that Bunpro plans to add/added since you did the import, it’s much easier to go back, get Bunpro to recognize the now-valid item, then re-add it properly to the list.
That’s all I’ve got for now; got family arriving. Will come back to pick this up later!
4 Likes
Thanks ! I hadn’t thought about asking ChatGPT….
2 Likes
I’m getting the following error while trying to import more vocabulary:
No included.reviewable_base_attribute array found on DataWIncludedObj for DeckContent: 63045
1 Like
I tested with the import of cowboy bebop, I use id JMDict.
Sometimes I had a failed import but re-import work, I do not understand why.
The result of import error of an item with an id is not practical as we only have the id we do not understand the word associates to.
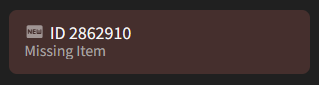
On import errors it could be interesting to have the words suggested to replace, which could be retrieved via input from other users.
It may be interesting to recover the import error list of different users and try to automatically resolve the most frequent ones.
I find the limit of 500 items per unit and 4000 by import a little low.
The first episode makes 464 items and my total file makes 4802 items with a filter on duplicates of previous words item.
And in a more global way it would be interesting to import a large file directly.
I used jmdict IDs because I had import fails with the first method, it works really well with it but I don’t find it very accessible.
I had to make a program to parse the xml The JMDict Project and make a database to find the right id for a word, there are probably other methods but given the large amount of words I risked having a performance problem for the generation of the file.
It could be simpler to have a more transparent solution where the conversion into ID is done via the server and the words are imported directly.
In the deck description, line returns are not managed correctly.

The feature is really interesting thanks to the team.
3 Likes
So I just started using the custom deck feature. I just started work at a Japanese company and they gave me permission to use Bunpro at work to look up grammar and vocabulary that I don’t know. So what I do is when I find something I don’t know from work, I search the word and now add it to my work vocab deck. I then usually try to add the sentence from work as an example. I find the custom deck feature to be useful to see my progress on work words since it’s kind of hard to find the vocabulary I’ve added to review that doesn’t have a JLPT level.
As an example, 仕掛かり. During my status report meetings, I always see 仕掛かり中 and then I added the sentence.
プロジェクトはまだ仕掛かり中です。
At work, it was originally a slide with ポロジェクト名 - 仕掛かり中
I think the following features would be helpful for me:
- On the standard search, where you can search for grammar and vocab, if there was an add to deck button, that would be helpful. Maybe this would only appear if you added a custom deck.
- On the add cards page, allow for a comma separated list to be searched, or space delaminated list. that will show words in the search.
- I know this would be hard, but maybe some kind of parsing of words where it will show similar words if something isn’t found. Sometimes I have vocabulary words I search that may be a compound word, but I don’t realize until I try to search with a different dictionary app like jisho.org.
— For example, I tried to find 仕掛かり中, but it would have been nice if 仕掛かり and 中 showed up since that word doesn’t exist. Or even just 仕掛かり. - If possible, allow for pasting a sentence and having all words in the sentence show up in the search. Again, I know this is a hard parsing problem. But it would still be helpful.
Thank you guys for all your hard work! I love everything you guys have done.
5 Likes
Hi there!
Can you please DM what you’re entering?
@Flutter @eefara @Magyarapointe @haldo @entropyofchaos
Looks like it’s back to the lab again! 
Will come back with a newer iteration some time later next week.
4 Likes
Don’t know if this has been asked before, but is there a way to add custom words when making a new deck? For example, I’m trying to make a deck with number-related vocab and 二時 for example just doesn’t exist. A simple way to create custom vocab with the japanese and english translation as well as furigana would be great.
3 Likes
This simple feature would theoretically also allow for the creation of kanji decks
2 Likes
I wonder what the best way to separate out chapters would be using @Flutter’s tool. I’m thinking of a novel, for example, since that’s what I’ve been playing with, and my thought is that it would be nice if I could take each new grammar/vocab item and add it in the chapter it first appears in, each chapter being a separate unit.
How does your tool currently organize the output it generates, Flutter?
2 Likes
The program currently randomizes the order within each section/file because that is the most elegant/performant way to do it. For manga the solution could be putting each chapter in a separate folder and treating the volume folder as a manga parent folder, that would definitely work. Same could be done with a PDF if you split it up into separate files for each chapter.
I could definitely change my program to keep the order, I think it shouldnt affect performance too bad, but I believe your approach might be unrealistic because imagine you’re on chapter/volume 13, how long might it take for you to find a word that hasn’t appeared yet? I don’t actually know how hard it would be, it sounds like it could be quite tedious, but maybe it’d be worth trying out. Let me know what you think, I’d definitely appreciate more input or suggestions on this (feel free to open an issue on the github page, I don’t wanna clog up the forum here).
2 Likes
Or you could split the epub by chapter, creating specific epubs for each, and then run @Flutter 's tool on it. That’s what I do. There’s a Calibre plug-in for that.
Could you do that for epubs too ? That way, we could use Calibre to split the epub in several files, put them in a folder, and run your program on it.
3 Likes
Of course, just provide the folder with the epubs and use the --separate (and --id for bunpro specifically) option. This works for all file types, it will create sections for each file (or sub-folder in the case of manga)
2 Likes
I couldn’t get it to work, but it’s not your program, it’s something that Calibre does when splitting (everything works fine with an un-splitted epub). I ended up reconverting to .txt, making a folder of those, and then it works
2 Likes
If you could send me those epub files that don’t work maybe I could try to troubleshoot it but if it really is Calibre then that’s a shame. Maybe there are other ways to do it?
2 Likes
Sure, I’ll send you the zipped folder with the split epubs inside. I tried running your program on the (unzipped) folder with --separate, and later tried running it on each file, I always ran into the same error :
/ebooklib/epub.py", line 358, in get_body_content
if len(html_root.find(‘body’)) != 0:
TypeError: object of type ‘NoneType’ has no len()
But running on a folder with text files with flags --separate --id --type txt worked flawlessly.
And as you suggested, I asked ChatGPT… which suggested a patch to epub.py, which caused another error to appear… at which point I gave up.
But I really think it has somehow to do with manipulating the epub file in Calibre, because when I tried with another epub that I had split, then merged, then reconverted, it gave another, different error. I guess epub editing is just above my paygrade…
Just send me an email and I’ll send you the file (it’s a burner account, and since the novel is not public domain, I don’t want to send the whole text with a public link here…)
2 Likes
So I finally uploaded the whole vocab list for the novel I’m reading, by chapter, and I ran into a couple of strange things :
- The first import I did was over 500 items (I hadn’t checked before) : it filled the Unit I had created, and spilled over a new one, but the first unit was filled with 501 items, which mean I couldn’t save it. I deleted on item, and only then could I save. The extra item had been added, there wasn’t a problem with parsing/recognizing it
- After that, I did several other imports over 500 items. This behaviour (first unit filled with 501 items) didn’t happen again, but Bunpro created extra units apparently before checking for duplicates : that is, I ended up with, for exemple, 3 units (the one I had created, and two “overflow” units), but all were much below 500 items (One import ended with two units of 335 and 319 items, one ended with three units of 237, 237 and 62 items, the last one ended with two items of 130 and 97 items)
3 Likes